Dataset Examples
From left to right: RGB input, depth map, and canonical coordinate map.
Results of Face Anything on NeRSemble.
From left to right: input videos, reconstructions with tracking.
Results of Face Anything on VFHQ.
From left to right: input videos, reconstructions with tracking.
Accurate reconstruction and tracking of dynamic human faces from image sequences is challenging because non-rigid deformations, expression changes, and viewpoint variations occur simultaneously, creating significant ambiguity in geometry and correspondence estimation. We present a unified method for high-fidelity 4D facial reconstruction based on canonical facial point prediction, a representation that assigns each pixel a normalized facial coordinate in a shared canonical space. This formulation transforms dense tracking and dynamic reconstruction into a canonical reconstruction problem, enabling temporally consistent geometry and reliable correspondences within a single feed-forward model. By jointly predicting depth and canonical coordinates, our method enables accurate depth estimation, temporally stable reconstruction, dense 3D geometry, and robust facial point tracking within a single architecture. We implement this formulation using a transformer-based model that jointly predicts depth and canonical facial coordinates, trained using multi-view geometry data that non-rigidly warps into the canonical space. Extensive experiments on image and video benchmarks demonstrate state-of-the-art performance across reconstruction and tracking tasks, achieving approximately 3$\times$ lower correspondence error and faster inference than prior dynamic reconstruction methods, while improving depth accuracy by 16%. These results highlight canonical facial point prediction as an effective foundation for unified feed-forward 4D facial reconstruction. The model, dataset, and code will be publicly available.
Dataset Examples
From left to right: RGB input, depth map, and canonical coordinate map.
4D Reconstruction Results Comparisons.
We present comparisons against face-specific depth prediction methods such as DAViD and Sapiens, as well as dynamic reconstruction approaches like V-DPM.
Tracking Comparisons.
Comparison with state-of-the-art tracking methods, including Pixel3DMM and V-DPM, demonstrates that our approach achieves higher tracking accuracy and reconstruction fidelity.
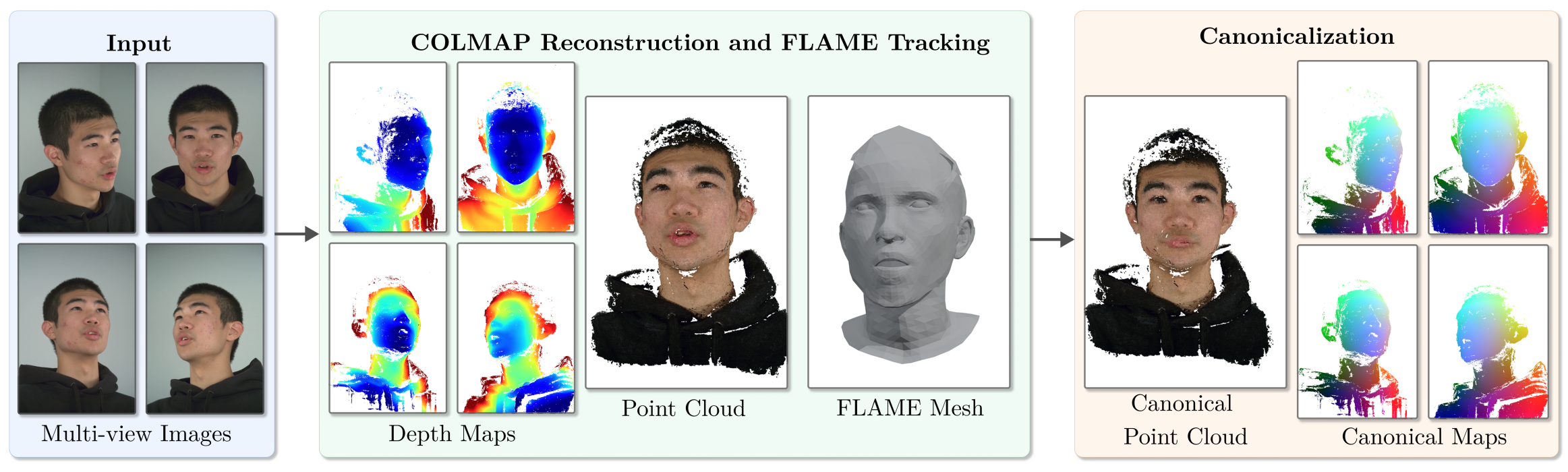
1. We construct a large-scale dataset based on NeRSemble, leveraging synchronized multi-view captures with calibrated cameras.
2. We select diverse frames per subject using facial expression and pose sampling based on MediaPipe estimates.
3. For each selected timestamp, we reconstruct high-quality geometry using COLMAP to obtain depth maps and dense point clouds.
4. We perform FLAME-based tracking to align reconstructed geometry into a shared canonical space across frames and identities.
5. Canonical maps are generated by transferring FLAME-based deformations to reconstructed points, providing dense supervision for correspondence learning.
6. The final dataset contains RGB images, depth maps, and canonical maps with consistent geometry and correspondences across viewpoints and time.
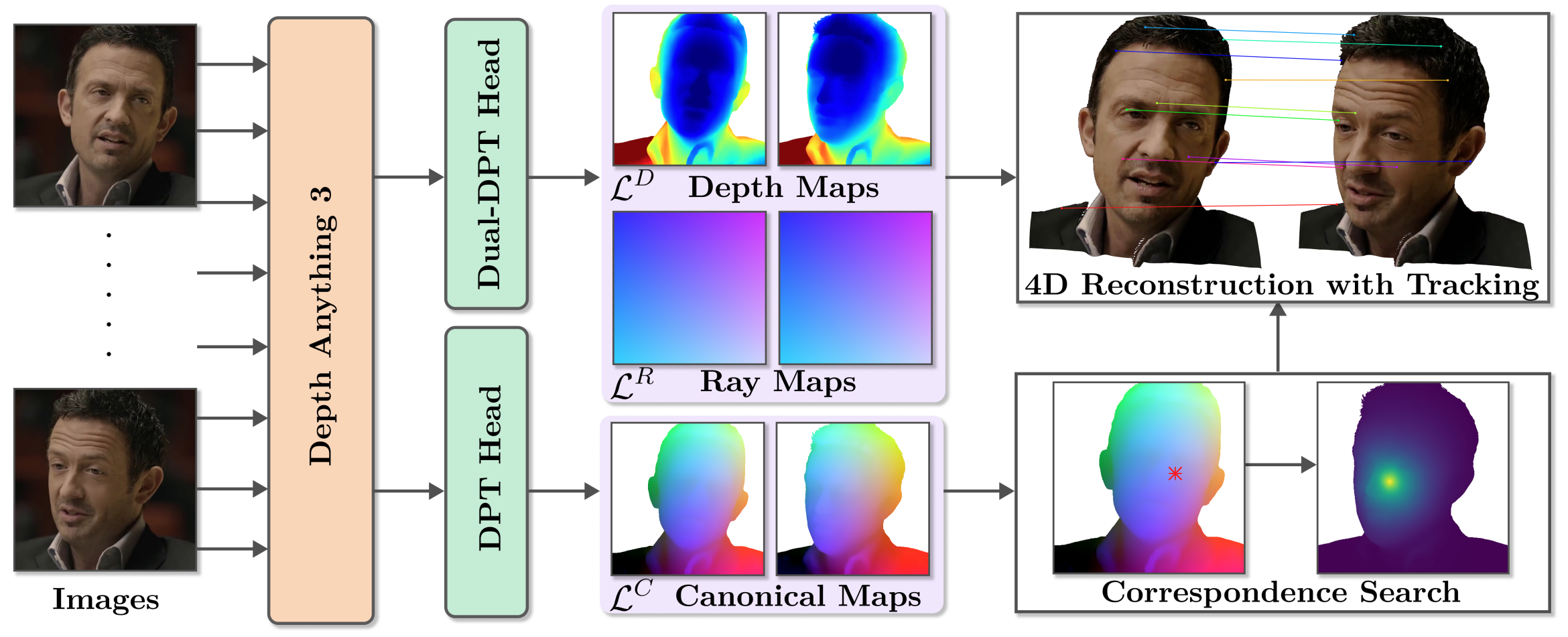
1. We propose a transformer-based architecture that jointly predicts depth, ray maps, and canonical facial maps from one or more input images.
2. Instead of estimating motion between frames, we formulate tracking as canonical map prediction, assigning each pixel a normalized facial coordinate in a shared canonical space.
3. The model processes multi-image inputs using a DPT-style head to produce dense predictions for geometry and correspondences in a single forward pass.
4. Dense correspondences are obtained via nearest-neighbor search in canonical space, enabling efficient and temporally consistent tracking.
5. The network is trained in two stages: first pretraining on DAViD for facial priors, followed by finetuning with canonical supervision.
@article{kocasari2026face,
title={Face Anything: 4D Face Reconstruction from Any Image Sequence},
author={Kocasari, Umut and Giebenhain, Simon and Shaw, Richard and Nie{\ss}ner, Matthias},
journal={arXiv preprint arXiv:2604.19702},
year={2026}
}